
The title of this blog post is a phrase coined by Paul Wouters and Rodrigo Costas in their 2012 publication Users, Narcissism and Control—Tracking the Impact of Scholarly Publications in the 21st Century. By “technologies of narcissism”, Wouters and Costas mean tools that allow individuals to rapidly assess the impact, usage and influence of their publications without much effort. One of the main points that Wouters and Costas try to convey is that individuals using technologies of narcissism must exercise “great care and caution” due to the individual level focus of altmetrics.
I first recall noticing altmetrics associated to one of my papers after publishing the paper “Bioinformatics for Whole-Genome Shotgun Sequencing of Microbial Communities” in PLoS Computational Biology in 2005. Public Library of Science (PLoS) was one of the first publishers to collect and display views and downloads of papers, and I remember being intrigued the first time I noticed my paper statistics. Eventually I developed the habit of revisiting the paper website frequently to check “how we were doing”. I’m probably responsible for at least a few dozen of the downloads that led to the paper making the “top ten” list the following year. PLoS Computational Biology even published a paper where they displayed paper rankings (by downloads). Looking back, while PLoS was a pioneer in developing technologies of narcissism, it was the appetite for them from individuals such as myself that drove a proliferation of new metrics and companies devoted to disseminating them. For example, a few years later in 2012, right when Wouters and Costas were writing about technologies of narcissism, Altmetric.com was founded and today is a business with millions of dollars in revenue, dozens of employees, and a name that is synonymous with the metrics they measure.
Today Altmetric.com’s “Attention Score” is prominently displayed alongside articles in many journals (for example all of the publications of the Microbial Society) and even bioRxiv displays them. In fact, the importance of altmetrics to bioRxiv is evident as they are mentioned in the very first entry of the bioRxiv FAQ, which states that “bioRxiv provides usage metrics for article views and PDF downloads, as well as altmetrics relating to social media coverage. These metrics will be inaccurate and underestimate actual usage in article-to-article comparisons if an article is also posted elsewhere.” Altmetric.com has worked hard to make it easy for anyone to embed the “Altmetric Attention Score” on their website, and in fact some professors now do so:

What does Altmetric.com measure? The details may surprise you. For example, Altmetric tracks article mentions in Wikipedia, but only in the English, Finnish and Swedish Wikipedias. Tweets, retweets and quoted tweets of articles are tracked, but not all of them. This is because Altmetric.com was cognizant of the possibility of “gaming the system” from the outset and it therefore looks for “evidence of gaming” to try to defend against manipulation of its scores. The “Gaming altmetrics” blogpost by founder Euan Adie in 2013 is an interesting read. Clearly there have been numerous attempts to manipulate the metrics they measure. He writes “We flag up papers this way and then rely on manual curation (nothing beats eyeballing the data) to work out exactly what, if anything, is going on.”
Is anything going on? It’s hard to say. But here are some recent comments on social media:
“can I now use (download) statistics to convince Nature Methods to take my paper…?”

Perhaps this exchange is tongue-in-cheek but notice that by linking to a bioRxiv preprint the second tweet in the series above actually affected the Altmetric Attention Score of that preprint:

Here is another exchange:

Apparently they are not the first to have this idea:

The last tweet is by a co-founder of bioRxiv. These recent “jokes” (I suppose?) about altmetrics are in response to a recent preprint by Abdill and Blekhman (note that I’ve just upped the Altmetric Attention Score of the preprint by linking to it from this blog; Altmetric.com tracks links from manually curated lists of blogs). The Abdill-Blekhman preprint included an analysis showing a strong correlation between paper downloads and the impact factor of journals where they are published:

The analogous plot showing the correlation between tweets and citations per preprint (averaged by journal where they ended up being published) was made by Sina Booeshaghi and Lynn Yi last year (GitHub repository here):

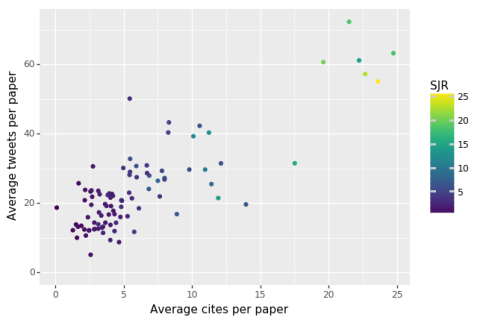
There are some caveats to the Booeshaghi-Yi analysis (the number of tweets per preprint is capped at 100) but it shows a similar trend to the Abdill-Blekhman analysis. One question which these data raise (and the convenient API by Abdill and Blekhman makes possible to study) is what is the nature of this correlation? Are truly impactful results in preprints being recognized as such (independently) by both journal reviewers/editors and scientists via twitter, or are the altmetrics of preprints directly affecting where they end up being published? The latter possibility is disturbing if true. Twitter activity is highly biased and associated with many factors that have nothing to do with scientific interest or relevance. For example, women are less influential on twitter than men (men are twice as likely to be retweeted as women). Thus, the question of causation in this case is not just of academic interest, it is also of career importance for individuals, and important for science as a whole. The data of Abdill and Blekhman will be useful in studying the question, and are an important starting point to assimilate and build on. I am apparently not the only person who thinks so; Abdill and Blekhman’s preprint is already “highly downloaded”, as can be seen on a companion website to the preprint called Rxivist.
The Rxivist website is useful for browsing the bioRxiv, but it does something else as well. For the first time, it makes accessible two altmetric statistics (paper downloads and tweets) via “author leaderboards”. Unlike Altmetric.com, which appears to carefully (and sometimes) manually curates the statistics going into its final score, and which acts against manipulation of tweets by filtering for bots, the Rxivist leaderboards are based on raw data. This is what a leaderboard of “papers downloaded” looks like:

The fact is that Stephen Floor is right; it is already accepted that the number of times a preprint has been downloaded is relevant and important:
But this raises a question, are concerns about gaming the system overblown? A real problem? How hard is it, really, to write a bot to boost one’s download statistics? Has someone done it already?
Here is a partial answer to the questions above in the form of a short script that downloads any preprint (also available on the blog GitHub repository where the required companion chromedriver binary is also available):

This script highlights a significant vulnerability in raw altmetric scores such as “number of times downloaded” for a preprint or paper. The validation is evident in the fact that in the course of just three days the script was able to raise the number of downloads for the least downloaded Blekhman et al., preprint (relative to its age) from 477 to 33,540. This now makes it one of the top ten downloaded preprints of all time. This is not a parlor trick or a stunt. Rather, it reveals a significant vulnerability in raw altmetrics, and emphasizes that if individuals are to be ranked (preferably not!) and those rankings broadly distributed, at least the rankings should be done on the basis of metrics that are robust to trivial attacks and manipulations. To wit, I am no fan of the h-index, and while it is a metric that can be manipulated, it is certainly much harder to manipulate than the number of downloads, or tweets, of a paper.
The scientific community would be remiss to ignore the proliferation of technologies of narcissism. These technologies can have real benefit, primarily by providing novel ways to help researchers identify interesting and important work that is relevant to the questions they are pursuing. Furthermore, one of the main advantages of the open licensing of resources such as bioRxiv or PLoS is that they permit natural language processing to facilitate automatic prioritization of articles, search for relevant literature, and mining for specific scientific terms (see e.g., Huang et al. 2016). But I am loathe to accept a scientific enterprise that rewards winners of superficial, easily gamed, popularity contests.

8 comments
Comments feed for this article
January 29, 2019 at 11:00 am
Resigned PostDoc
Young scientists (PhDs/PostDocs) have accepted the fact that academia is nowadays more about PI egos, publications and getting funding than actual research. We are lacking true scientific role models.That is why many leave academia and look for purpose elsewhere.
January 30, 2019 at 11:42 am
Young PhD
😦
February 9, 2019 at 4:19 am
Javier B.
The obsession with metrics is destroying intellectual life. Forget that the premise that more citations means better work is obviously wrong (more citations just means something is easily understood or appealing to a lot of people who may be, and often are, complete idiots). Forget that people like the narcissistic owner of this blog spend time downloading their own articles. Forget that hacking for patterns in biological data is considered science. The idea that one can linearly rank intellectual achievements is disgusting enough by itsellf.
January 29, 2019 at 8:12 pm
Abby Dernburg
Thanks for this thoughtful analysis. Unfortunately, there is no aspect of scientific assessment that is immune to gaming, or to less malicious foibles of human nature — e.g. the strength of a PI’s professional/personal network clearly impacts evaluation of their grant applications and manuscripts, independent of the novelty and implications of the ideas & results. But new technologies & metrics give rise to new ways to game the system, and it’s essential to know how that works to help mitigate the problems.
January 30, 2019 at 12:27 pm
Richard Sever
Hi Lior. Thanks for drawing this to our attention. A few points:
1. BioRxiv itself does no ranking of papers or authors based on these or any other metrics – in part for the very reasons you give above.
2. We do provide metrics for individual articles, primarily because many authors seem to value them. We always caution against overinterpreting/overusing these.
3. We employ robust technology to filter out various bots and will be investigating cases where these may go under our radar. Inevitably this is somewhat of an arms race but it is something we are concerned about and devote attention to.
January 31, 2019 at 7:41 pm
Tim W.
If robust technology is being used to filter out bots why did this very simple bot inflate the downloads of this paper by 33k? You replied to this blog post but the download stat for the paper in question remains…
February 19, 2019 at 1:12 am
Sebastian Kurscheid
Hi Lior,
An insightful post – I am just a bit surprised that you took aim at Mark Robinson. He is a very important contributor to the bioinformatics community and I think that his commitment to transparent and robust methodologies is apparent in all of his work. Just take a look at the edgeR documentation. Which is still being updated – in contrast to so many other bioinformatics packages, including your own. To accuse him of narcissism for utilising a metric that captures a more real-time impact is a bit of poor form.
February 19, 2019 at 1:25 am
Lior Pachter
Hi Sebastian,
Thanks for your comment. I agree with your characterization of Mark Robinson’s documentation as transparent, robust, and up-to-date, thus constituting an important contribution to the bioinformatics community. I don’t believe that his linking to his paper altmetric scores on his website detracts in any way from the documentation of his software. However the advertising of altmetric scores by an influential member of the bioinformatics community (which we both agree he is), does play a role, for better or for worse, in the proliferation of technologies of narcissism, which is what the post is about.