
If you haven’t heard about Clubhouse yet… well, it’s the latest Silicon Valley unicorn, and the popular new chat hole for thought leaders. I heard about it for the first time a few months ago, and was kindly offered an invitation (Club house is invitation only!) so I could explore what it is all about. Clubhouse is an app for audio based social networking, and the content is, as far as I can tell, a mixed bag. I’ve listened to a handful of conversations hosted on the app.. topics include everything from bitcoin to Miami. It was interesting, at times, to hear the thoughts and opinions of some of the discussants. On the other hand, there is a lot of superficial rambling on Clubhouse as well. During a conversation about genetics I heard someone posit that biology has a lot to learn from the fashion industry. This was delivered in a “you are hearing something profound” manner, by someone who clearly knew nothing about either biology or the fashion industry, which is really too bad, because the fashion industry is quite interesting and I wouldn’t be surprised at all if biology has something to learn from it. Unfortunately, I never learned what that is.
One of the regulars on Clubhouse is Noor Siddiqui. You may not have heard of her; in fact she is officially “not notable”. That is to say, she used to have a Wikipedia page but it was deleted on the grounds that there is nothing about her that indicates notability, which is of course notable in and of itself… a paradox that says more about Wikipedia’s gatekeeping than Siddiqui (Russell 1903, Litt 2021). In any case, Siddiqui was recently part of a Clubhouse conversation on “convergence of genomics and reproductive technology” together with Carlos Bustamante (advisor to cryptocurrency based Luna DNA and soon to be professor of business technology at the University of Miami) and Balaji Srinivasan (bitcoin angel investor and entrepreneur). As it happens, Siddiqui is the CEO of a startup called “Orchid Health“, in the genomics and reproductive technology “space”. The company promises to harness “population genetics, statistical modeling, reproductive technologies, and the latest advances in genomic science” to “give parents the option to lower a future child’s genetic risk by creating embryos through in IVF and implanting embryos in the order that can reduce disease risk.” This “product” will be available later this year. Bustamante and Srinivasan are early “operators and investors” in the venture.
Orchid is not Siddiqui’s first startup. While she doesn’t have a Wikipedia page, she does have a website where she boasts of having (briefly) been a Thiel fellow and, together with her sister, starting a company as a teenager. The idea of the (briefly in existence) startup was apparently to help the now commercially defunct Google Glass gain acceptance by bringing the device to the medical industry. According to Siddiqui, Orchid is also not her first dive into statistical modeling or genomics. She notes on her website that she did “AI and genomics research”, specifically on “deep learning for genomics”. Such training and experience could have been put to good use but…
Polygenic risk scores and polygenic embryo selection
Orchid Health claims that it will “safely and naturally, protect your baby from diseases that run in your family” (the slogan “have healthy babies” is prominently displayed on the company’s website). The way it will do this is to utilize “advances in machine learning and artificial intelligence” to screen embryos created through in-vitro fertilization (IVF) for “breast cancer, prostate cancer, heart disease, atrial fibrillation, stroke, type 2 diabetes, type 1 diabetes, inflammatory bowel disease, schizophrenia and Alzheimer’s“. What this means in (a statistical geneticist’s) layman’s terms is that Orchid is planning to use polygenic risk scores derived from genome-wide association studies to perform polygenic embryo selection for complex diseases. This can be easily unpacked because it’s quite a simple proposition, although it’s far from a trivial one- the statistical genetics involved is deep and complicated.
First, a single-gene disorder is a health problem that is caused by a single mutation in the genome. Examples of such disorders include Tay-Sachs disease, sickle cell anaemia, Huntington’s disease, Duchenne muscular dystrophy, and many other diseases. A “complex disease”, also called a multifactorial disease, is a disease that has a genetic component, but one that involves multiple genes, i.e. it is not a single-gene disorder. Crucially, complex diseases may involve effects of environmental factors, whose role in causing disease may depend on the genetic composition of an individual. The list of diseases on Orchid’s website, including breast cancer, prostate cancer, heart disease, atrial fibrillation, stroke, type 2 diabetes, type 1 diabetes, inflammatory bowel disease, schizophrenia and Alzheimer’s disease are all examples of complex (multifactorial) diseases.
To identify genes that associate with a complex disease, researchers perform genome-wide association studies (GWAS). In such studies, researchers typically analyze several million genomic sites in a large numbers of individuals with and without a disease (used to be thousands of individuals, nowadays hundreds of thousands or millions) and perform regressions to assess the marginal effect at each locus. I italicized the word associate above, because genome-wide association studies do not, in and of themselves, point to genomic loci that cause disease. Rather, they produce, as output, lists of genomic loci that have varying degrees of association with the disease or trait of interest.
Polygenic risk scores (PRS), which the Broad Institute claims to have discovered (narrator: they were not discovered at the Broad Institute), are a way to combine the multiple genetic loci associated with a complex disease from a GWAS. Specifically, a PRS 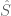
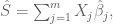
where the sum is over 
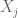
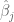
While much of the discussion around PRS applications centers on applications such as determining diagnostic testing frequency (Wald and Old 2019), polygenic embryo selection (PES) posits that polygenic risk scores should be taken a step further and evaluated for embryos to be used as a basis for discarding, or selecting, specific embryos for in vitro fertilization implantation. The idea has been widely criticized and critiqued (Karavani et al. 2019). It has been described as unethical, morally repugnant, and concerns about its use for eugenics have been voiced by many. Underlying these criticisms is the fact that the technical issues with PES using PRS are manifold.
Poor penetrance
The term “penetrance” for a disease refers to the proportion of individuals with a particular genetic variant that have the disease. Many single-gene disorders have very high penetrance. For example, F508del mutation in the CFTR gene is 100% penetrant for cystic fibrosis. That is, 100% of people who are homozygous for this variant, meaning that both copies of their DNA have a deletion of the phenylalanine amino acid in position 508 of their CFTR gene, will have cystic fibrosis. The vast majority of variants associated with complex diseases have very low penetrance. For example, in schizophrenia, the penetrance of “high risk” de novo copy number variants (in which there are variable copies of DNA at a genomic loci) was found to be between 2% and 7.4% (Vassos et al 2010). The low penetrance at large numbers of variants for complex diseases was precisely the rationale for developing polygenic risk scores in the first place, the idea being that while individual variants yield small effects, perhaps in (linear) combination they can have more predictive power. While it is true that combining variants does yield more predictive power for complex diseases, unfortunately the accuracy is, in absolute terms, very low.
The reason for low predictive power of PRS is explained well in (Wald and Old 2020) and is illustrated for coronary artery disease (CAD) in (Rotter and Lin 2020):

The issue is that while the polygenic risk score distribution may indeed be shifted for individuals with a disease, and while this shift may be statistically significant resulting in large odds ratios, i.e. much higher relative risk for individuals with higher PRS, the proportion of individuals in the tail of the distributions who will or won’t develop the disease will greatly affect the predictive power of the PRS. For example, Wald and Old note that PRS for CAD from (Khera et al. 2018) will confer a detection rate of only 15% with a false positive rate of 5%. At a 3% false positive rate the detection rate would be only 10%. This is visible in the figure above, where it is clear that control of the false positive right (i.e. thresholding at the extreme right-hand side with high PRS score) will filter out many (most) affected individuals. The same issue is raised in the excellent review on PES of (Lázaro-Muńoz et al. 2020). The authors explain that “even if a PRS in the top decile for schizophrenia conferred a nearly fivefold increased risk for a given embryo, this would still yield a >95% chance of not developing the disorder.” It is worth noting in this context, that diseases like schizophrenia are not even well defined phenotypically (Mølstrøm et al. 2020), which is another complex matter that is too involved to go into detail here.
In a recent tweet, Siddiqui describes natural conception as a genetic lottery, and suggests that Orchid Health, by performing PES, can tilt the odds in customers’ favor. To do so the false positive rate must be low, or else too many embryos will be discarded. But a 15% sensitivity is highly problematic considering the risks inherent with IVF in the first place (Kamphuis et al. 2014):

To be concrete, an odds ratio of 2.8 for cerebral palsy needs to be balanced against the fact that in the Khera et al. study, only 8% of individuals had an odds ratio >3.0 for CAD. Other diseases are even worse, in this sense, than CAD. In atrial fibrillation (one of the diseases on Orchid Health’s list), only 9.3% of the individuals in the top 0.44% of the atrial fibrillation PRS actually had atrial fibrillation (Choi et al 2019).As one starts to think carefully about the practical aspects and tradeoffs in performing PES, other issues, resulting from the low penetrance of complex disease variants, come into play as well. (Lencz et al. 2020) examine these tradeoffs in detail, and conclude that “the differential performance of PES across selection strategies and risk reduction metrics may be difficult to communicate to couples seeking assisted reproductive technologies… These difficulties are expected to exacerbate the already profound ethical issues raised by PES… which include stigmatization, autonomy (including “choice overload”, and equity. In addition, the ever-present specter of eugenics may be especially salient in the context of the LRP (lowest-risk prioritization) strategy.” They go on to “call for urgent deliberations amongst key stakeholders (including researchers, clinicians, and patients) to address governance of PES and for the development of policy statements by professional societies.”
Pleiotropy predicaments
I remember a conversation I had with Nicolas Bray several years ago shortly after the exciting discovery of CRISPR/Cas9 for genome editing, on the implications of the technology for improving human health. Nick pointed out that the development of genomics had been curiously “backwards”. Thirty years ago, when human genome sequencing was beginning in earnest, the hope was that with the sequence at hand we would be able to start figuring out the function of genes, and even individual base pairs in the genome. At the time, the human genome project was billed as being able to “help scientists search for genes associated with human disease” and it was imagined that “greater understanding of the genetic errors that cause disease should pave the way for new strategies in diagnosis, therapy, and disease prevention.” Instead, what happened is that genome editing technology has arrived well before we have any idea of what the vast majority of the genome does, let alone the implications of edits to it. Similarly, while the coupling of IVF and genome sequencing makes it possible to select embryos based on genetic variants today, the reality is that we have no idea how the genome functions, or what the vast majority of genes or variants actually do.
One thing that is known about the genome is that it is chock full of pleiotropy. This is statistical genetics jargon for the fact that variation at a single locus in the genome can affect many traits simultaneously. Whereas one might think naïvely that there are distinct genes affecting individual traits, in reality the genome is a complex web of interactions among its constituent parts, leading to extensive pleiotropy. In some cases pleiotropy can be antagonistic, which means that a genomic variant may simultaneously be harmful and beneficial. A famous example of this is the mutation to the beta globin gene that confers malaria resistance to heterozygotes (individuals with just one of their DNA copies carrying the mutation) and sickle cell anemia to homozygotes (individuals with both copies of their DNA carrying the mutation).
In the case of complex diseases we don’t really know enough, or anything, about the genome to be able to truly assess pleiotropy risks (or benefits). But there are some worries already. For example, HLA Class II genes are associated with Type I and non-insulin treated Type 2 diabetes (Jacobi et al 2020), Parkinson’s disease (e.g. James and Georgopolous 2020, which also describes an association with dementia) and Alzheimer’s (Wang and Xing 2020). PES that results in selection against the variants associated with these diseases could very well lead to population susceptibility to infectious disease. Having said that, it is worth repeating that we don’t really know if the danger is serious, because we don’t have any idea what the vast majority of the genome does, nor the nature of antagonistic pleiotropy present in it. Almost certainly by selecting for one trait according to PRS, embryos will also be selected for a host of other unknown traits.
Thus, what can be said is that while Orchid Health is trying to convince potential customers to not “roll the dice“, by ignoring the complexities of pleiotropy and its implications for embryo selection, what the company is actually doing is in fact rolling the dice for its customers (for a fee).

Population problems
One of Orchid Health’s selling points is that unlike other tests that “look at 2% of only one partner’s genome…Orchid sequences 100% of both partner’s genomes” resulting in “6 billion data points”. This refers to the “couples report”, which is a companion product of sorts to the polygenic embryo screening. The couples report is assembled by using the sequenced genomes of parents to simulate the genomes of potential babies, each of which is evaluated for PRS’ to provide a range of (PRS based) disease predictions for the couples potential children. Sequencing a whole genome is a lot more expensive that just assessing single nucleotide polymorphisms (SNPs) in a panel. That may be one reason that most direct-to-consumer genetics is based on polymorphism panels rather than sequencing. There is another: the vast majority of variation in the genome occurs at a known polymorphic sites (there are a few million out of the approximately 3 billion base pairs in the genome), and to the extent that a variant might associate with a disease, it is likely that a neighboring common variant, which will be inherited together with the causal one, can serve as a proxy. There are rare variants that have been shown to associate with disease, but whether or not they explain can explain a large fraction of (genetic) disease burden is still an open question (Young 2019). So what has Siddiqui, who touts the benefits of whole-genome sequencing in a recent interview, discovered that others such as 23andme have missed?
It turns out there is value to whole-genome sequencing for polygenic risk score analysis, but it is when one is performing the genome-wide association studies on which the PRS are based. The reason is a bit subtle, and has to do with differences in genetics between populations. Specifically, as explained in (De La Vega and Bustamante, 2018), variants that associate with a disease in one population may be different than variants that associate with the disease in another population, and whole-genome sequencing across populations can help to mitigate biases that result when restricting to SNP panels. Unfortunately, as De La Vega and Bustamante note, whole-genome sequencing for GWAS “would increase costs by orders of magnitude”. In any case, the value of whole-genome sequencing for PRS lies mainly in identifying relevant variants, not in assessing risk in individuals.
The issue of population structure affecting PRS unfortunately transcends considerations about whole-genome sequencing. (Curtis 2018) shows that PRS for schizophrenia is more strongly associated with ancestry than with the disease. Specifically, he shows that “The PRS for schizophrenia varied significantly between ancestral groups and was much higher in African than European HapMap subjects. The mean difference between these groups was 10 times as high as the mean difference between European schizophrenia cases and controls. The distributions of scores for African and European subjects hardly overlapped.” The figure from Curtis’ paper showing the distribution of PRS for schizophrenia across populations is displayed below (the three letter codes at the bottom are abbreviations for different population groups; CEU stands for Northern Europeans from Utah and is the lowest).

The dependence of PRS on population is a problem that is compounded by a general problem with GWAS, namely that Europeans and individuals of European descent have been significantly oversampled in GWAS. Furthermore, even within a single ancestry group, the prediction accuracy of PRS can depend on confounding factors such as socio-economic status (Mostafavi et al. 2020). Practically speaking, the implications for PES are beyond troubling. The PRS scores in the reports customers of Orchid Health may be inaccurate or meaningless due to not only the genetic background or admixture of the parents involved, but also other unaccounted for factors. Embryo selection on the basis of such data becomes worse than just throwing dice, it can potentially lead to unintended consequences in the genomes of the selected embryos. (Martin et al. 2019) show unequivocally that clinical use of polygenic risk scores may exacerbate health disparities.
People pathos
The fact that Silicon Valley entrepreneurs are jumping aboard a technically incoherent venture and are willing to set aside serious ethical and moral concerns is not very surprising. See, e.g. Theranos, which was supported by its investors despite concerns being raised about the technical foundations of the company. After a critical story appeared in the Wall Street Journal, the company put out a statement that
“[Bad stories]…come along when you threaten to change things, seeded by entrenched interests that will do anything to prevent change, but in the end nothing will deter us from making our tests the best and of the highest integrity for the people we serve, and continuing to fight for transformative change in health care.”
While this did bother a few investors at the time, many stayed the course for a while longer. Siddiqui uses similar language, brushing off criticism by complaining about paternalism in the health care industry and gatekeeping, while stating that
“We’re in an age of seismic change in biotech – the ability to sequence genomes, the ability to edit genomes, and now the unprecedented ability to impact the health of a future child.”
Her investors, many of whom got rich from cryptocurrency trading or bitcoin, cheer her on. One of her investors is Brian Armstrong, CEO of Coinbase, who believes “[Orchid is] a step towards where we need to go in medicine.” I think I can understand some of the ego and money incentives of Silicon Valley that drive such sentiment. But one thing that disappoints me is that scientists I personally held in high regard, such as Jan Liphardt (associate professor of Bioengineering at Stanford) who is on the scientific advisory board and Carlos Bustamante (co-author of the paper about population structure associated biases in PRS mentioned above) who is an investor in Orchid Health, have associated themselves with the company. It’s also very disturbing that Anne Wojcicki, the CEO of 23andme whose team of statistical geneticists understand the subtleties of PRS, still went ahead and invested in the company.
Conclusion
Orchid Health’s polygenic embryo selection, which it will be offering later this year, is unethical and morally repugnant. My suggestion is to think twice before sending them three years of tax returns to try to get a discount on their product.


34 comments
Comments feed for this article
April 12, 2021 at 3:41 pm
kmbunday
Thank you very much for this very informative post. I will share this widely with other readers.
April 12, 2021 at 3:41 pm
Aaron Tran
Wonderful article. The figure comparing the polygenic scores of the control and actual patients for the coronary artery disease study was quite enlightening. Is the similarity between both groups the result of genes having too little to do with the underlying disease itself, or a failure of the study design?
If it’s the former that sounds like a bad omen for bioinformatics.
April 12, 2021 at 4:15 pm
Tom Willis
Long-time listener, first-time caller.
‘Newscombe et al.’ should be ‘Newcombe et al.’
April 12, 2021 at 4:17 pm
Lior Pachter
Thanks. Fixed!
April 12, 2021 at 9:08 pm
Anonymous Reader
The ethical case against polygenic risk modification and the scientific case against doing it using current understanding are totally different. This posts conflates the two horribly and makes quite a few ad hominems against the CEO of Orchid.
First of all, whether a technology works is a totally different question from whether even attempting it is unethical. You clearly believe the latter but make arguments about the former. I’ll give an example. Female genital mutilation is a cultural practice undertaken on the basis of various cultural benefits like “curbing sex drive” and “increased cleanliness.” Does it actually achieve those things? Almost certainly not. But that is totally immaterial to whether I would consider it ethical to attempt it: it’s not — even if it did accomplish those things.
And so on and so forth.
The key question here is… why do you believe that it is acceptable to select against monogenic traits like Tay Sachs disease but not even ATTEMPT the same with polygenic ones? (Note: I’m not asserting that such a thing can be done as effectively or without bias.) But I’m asking why seem to believe even attempting it is wrong. I recognize the grotesque history of eugenics overshadows the debate, but again, you haven’t made a case for why it can’t ever be done ethically.
So with all that being said, you assert that Orchid is technically incoherent, but I am not so sure what that means. Clearly the science is primitive, but if I had to bet, I would guess that directionally, targeting polygenic risk scores would reduce rather than increase disease in babies. Whether that is a net “good” for society is a complex question that I don’t purport to have an answer to.
Respectfully,
AR
April 12, 2021 at 9:42 pm
Lior Pachter
In my opinion selling a product that has no scientific sound rationale and yet can, and likely will do harm, is unethical. My post explains why PES right now has no scientifically sound rationale, and also describes several ways in which it can do harm. I don’t know what the future holds in terms of our understanding of biology, nor do I know what technologies will exist in the future. I’m not particularly interested in speculating on that, nor do I think it’s relevant in terms of assessing what Orchid is doing right now. As I noted, in an interview the CEO stated that PES would be sold to Orchid customers later this year.
It’s true that separately from the science there are other ethical concerns about PES and Orchid. My post does not address them, nor is it even comprehensive on the science and technical aspects. Your point on that is fair and I acknowledge that much more could have been said. By way of example, someone pointed out today that I did not even discuss G x E (genotype-environment) interaction (https://twitter.com/KreitmanMartin/status/1381777015272001545).
April 12, 2021 at 11:24 pm
someone
You are posing personal attack on Noor Siddiqui and this is not acceptable. There should be difference between expressing “scientific integrity” vs character assassination.
Here are example of your character assassination:
“Orchid is not Siddiqui’s first startup. While she doesn’t have a Wikipedia page, she does have a website where she boasts of having (briefly) been a Thiel fellow and, together with her sister, starting a company as a teenager.”
Majority of entrepreneurs in Silicon-Vally started something else or failed at their pervious ventures before deciding what to work on. This is not a weakness.
By poking her “Wikipedia-Page” is un-notable or looking at her other “start-up” while she was very young, you are doing character assassination.
From reading your website and reading up your background, it seems that your knowledge on deep learning and recent advances in machine-learning models (in particular language models) and capabilities are fairly limited. It seems that you are an old-school computational biologist.
April 12, 2021 at 11:26 pm
Lior Pachter
I am certainly no expert on deep learning but FWIW I did just teach Caltech’s machine learning course CS155. A sample syllabus is available here: http://www.yisongyue.com/courses/cs155/2020_winter/
April 12, 2021 at 11:44 pm
someone
I was not able to find anything on deep-learning by looking at your publication list – maybe if you could point to one?
https://scholar.google.com/citations?user=DKfEcuEAAAAJ&hl=en
April 13, 2021 at 12:21 am
Your Honor
Who gives a shit whether Pachter decides to publish on deep learning or not. If he wanted to publish on deep learning, he would. If he chose to publish on hardcore number theory or algebraic topology, he would do that. At that level, it’s literally a matter of personal preference, and intellectual self expression. As one of the pre-eminent quantitative biologists in the entire world, he’s more than qualified to explain the things that this company is doing (which, spoiler alert, literally has nothing to do with deep learning, at all. Like, literally no relevance).
In terms of “character assassination,” the type of person who is arrogant enough to write their own Wikipedia page, when the Wikipedia community agrees that they don’t deserve one, is maybe not surprisingly the same type of person who think they’re qualified to tell people what kind of children to have. So it’s actually totally germane to the matter at hand, as the Judge/Magistrate in this courtroom blog, I will allow it.
April 14, 2021 at 12:13 pm
an observer
I do deep learning research and totally disagree with this rebuttal. Deep learning carries a major drawback in interpretability when compared to classical techniques. From my read of this article, it appears PRS is already quite noisy and based on a limited understanding of the underlying mechanisms.
A DL-based approach might provide better accuracy but risks exacerbating many of the other issues in this article. You’d be providing a score to customers on the cusp of a major decision with little insight into the contributing factors. You may also end up modeling a lot of noise that happens to correlate with desired outcomes in your sample.
Based on my own experiences, I am very skeptical of viewpoints that put down non-DL approaches and expertise. Also, part of being a startup founder is facing up to criticisms of your approach, background, and ideals. It comes with the territory.
April 14, 2021 at 5:15 pm
mickey
It’s definitely funny when “somebody” makes a vanity wikipedia article and it gets deleted for being un-notable.
It’s been the funniest thing about wikipedia since wikipedia popped up.
April 13, 2021 at 12:39 am
someone
“If he wanted to publish on deep learning, he would.” – sure, so as everybody else.
” literally has nothing to do with deep learning, at all.”
Could you please explain why?
“In terms of “character assassination,” the type of person who is arrogant enough to write their own Wikipedia page…”
How do you know if she wrote her own wikipedia page?
April 13, 2021 at 1:18 am
Your Honor
In terms of Wikipedia, will have to refer to the “DELETE” reasoning for the moderators: “(Still, WP:ENTREPRENEUR turns out to be right once again!)”
def. WP:ENTREPRENEUR: “On Wikipedia, Lankiveil’s Second Law is the observation that any 99.9% of biographies of a living people that contain the word “entrepreneur” in either the title or the first sentence of the article, will be a puff piece on a person of dubious notability, full of peacock terms, and most probably is an excellent example of vanispamcruftisement.”
def. vanispamcruftisement: “a portmanteau comprising several editorial faults which some Wikipedians see as cardinal sins: vanity (i.e., conflict of interest), spam, cruft, and advertisement.”
I guess I will have to trust the Wikipedia moderator’s expertise and pattern recognition here, in terms of the cardinal sin of entrepreneurial vanity. Or maybe it was some other concerned citizen who happened to clip every notable life event for a complete stranger, I guess we’ll never know.
In terms of deep learning, I’ll refer you to Equation 1 of Pachter’s post above. Polygenic Risk Scores (PRS), albeit apparently very complex in terms of their biological and anthropological interpretation (according to Science Twitter), are extremely simple, 2nd grade math: Multiplication (X times Beta_hat) and Addition (summed up across all genetic variants). They are applying effect estimates (Beta_hat) that are published by previous research papers, which they cite on their website. There is no application of deep learning in fitting these models (which are referred to as Generalized Linear Models: Linear, Logistic, Mixed Linear, etc.), or making these predictions (2nd grade math). The result of all of that are the distributions we see in Figure 1 above, and the summarization of these distributions using 3rd grade math (addition, and division this time).
April 13, 2021 at 1:04 am
someone
Happy to provide my email and we can move the convo-over the private email to be respectful of other readers – this issue is closely to my heart and comes from my countless personal experiences I have had as a female founder in the valley and why I disagree with “Professor Pachter” way of criticism.
Again, I do not mind he raised issues over “scientific-merits”, – but I do not think she knows Noor enough to be able to jump into the conclusion about her and pose it publicly before even know her.
This types of acquisition and hypocrisy can ruin someone’s life and that is not a joke.
It is possible to provide criticism but being respectful at the same time. I do not think his way of writing is respectful in any shape or forms.
He could simply email Noor and mention about what he thinks and asked her questions before making any conclusion like this.
The impact won’t be damaging to Noor only but it will be impacts many future female founders.
April 13, 2021 at 1:15 am
someone
he* /form* – sorry for typos. I accidentally post comment before finalizing my draft and can’t edit it + it is getting late here.
April 13, 2021 at 1:38 am
Your Honor
Wishing you and other female founders success and equality. But, from what I gather from this post and Twitter posts, she is doing a disservice to those female founders by potentially making a bad name for them.
April 13, 2021 at 8:54 am
public accountability
The topic of the post is a critque of a company that applies whole-genome PRS analyses to selectively reproduce humans. The technical basis and critcism is much older and much broader than one person, and examining the ethical/political implications is of much *much* greater importance for society than one person’s ambitions.
The goal of this company demands public scrutiny. Efforts to deflect into email are transparent attempts to cover for proto-eugenecists.
April 13, 2021 at 4:42 am
Ole K. Tørresen
“Orchid sequences 100% of both partner’s genomes” resulting in “6 billion data points”.” Shouldn’t this really have been 12 billion data points, since the haploid human genome is around 3 billion nucleotides, and humans are diploid? Bit strange that they forgot that. It could have doubled the number so it looked more impressive.
April 13, 2021 at 5:43 am
Lior Pachter
Good point! Bigly data!
April 13, 2021 at 9:25 am
gasstationwithoutpumps
I suspect that they are not doing haplotyping, as that is more expensive (either long-read sequencing or sequencing the parents), so they only have a genotype which gives one of 10 values (AA, AT, AC, AG, CC, CT, CG, GG,GT, TT) at each point of the genome (well, some other possible values when the data or mapping is bad, indicating even less information about the position).
April 13, 2021 at 7:34 am
Genesandcats
Regarding the g x e problem… given what you showed above about how different ancestry groups give radically different outcomes on PGS (in fact, these effects are stronger than the actual scores for disease itself), isn’t “accidental” racial eugenics a real possibility here?
If say, an African American couple who both have admixed European and African ancestry (common for AA couples) seek PES, wouldn’t it be a real possibility that the embryos selected would on average have a higher proportion of European ancestry because those alleles (by virtue of differences in societal treatment) will tend to associate with better health outcomes and thus higher PGS? Is any of this even considered by these models in a serious way?
P.S. I’m sorry if I submitted a similar comment twice, I was having device issues.
May 15, 2021 at 10:46 pm
U. Ploy
Interesting, so you are saying this is essentially an unwitting ploy to weed out non-European ancestry from the population. What you say is more likely to happen than what they advertise.
April 13, 2021 at 12:06 pm
anonymous
Gutsy founder. Though that doesn’t mean anything for the validity of the idea.
Familiar recipe for this flavor of biotech idea:
step 1: oversimplify science and brush aside ethics and develop a “vision”
step 2: get VC funding
step 3: move fast and break things, fake it until you make it, other cliches
step 4: maybe profit?
step 5: retrospectively justify what you did
Secret sauce here is Step 5 doesn’t have to come until 30 years later.
April 13, 2021 at 12:46 pm
anonymous
I should add the two other secret ingredients:
1) a legal clause that basically says “we are not promising you anything”:
“Your Results are based on currently available information in the medical literature and scientific databases, as well as laboratory informatics and algorithms that may be subject to change. You understand and agree that Orchid may, at its sole discretion, amend or modify your Test report based on any such changes. This may result in a change in your risk assessment; the reclassification of a variant; a change or update to a previously reported pharmacogenomic genotype or allele; or a reclassification of a reported diplotype. You hereby irrevocably waive any and all claims against Orchid for any amendment or modification of the Test report in accordance with Orchid’s standard operating procedures.”
2) And binding arbitration in Texas, if you have any disputes that you can’t resolve with them.
April 13, 2021 at 12:36 pm
Brian
Odd to conclude that it is unethical while ignoring the vast literature on the ethics of genetic enhancement, much of which has already discussed issues of pleiotropy, risk, uncertainty, etc. Allen Buchanan, Julian Savulescu, Jonathan Anomaly, and Christopher Gyngell have all addressed these issues in articles and in books. I’d start with books like “Better than Human?” by Buchanan and Creating Future People by Anomaly, and then identify specific areas of agreement or disagreement rather than trying to reinvent the wheel.
April 13, 2021 at 1:20 pm
golden_horde
It is useful to dissect things from a scientific point of view, which Lior has done quite well in this post. What has been said on PRS scores and effect sizes is summarized quite well by the author here IMHO (I work in the same field) Such subtleties are certainly not obvious and anybody giving advice on the technicalities and pitfalls of such scores without the scientific credentials (such as the authors you mention here who are NOT experts by any stretch on statistical genomics – they seem to be lawyers and economists) should not be taken very seriously. I’d rather hear what a respected scientist in this field has to say on related matters.
While I do not agree with Lior’s unnecessary shaming and overbearing commentary , his criticism of the science and ethics of a company making dubious claims is well justified.
April 14, 2021 at 10:10 am
JohnBuridan
Although, the author does a good job explaining the statistical limitations of this PES method, the author never explains the moral reasoning for why it is unethical and the linked to papers don’t either. I came here for the moral arguments and would like to see more complete syllogisms on this aspect of embryo selection.
April 14, 2021 at 10:18 am
Tim
Very tiny thing really unimportant to the full blog, but RE: the Broad Institute claim about having discovered polygenic risk scoring, I read that tweet as suggesting they discovered that specific heart attack-related process — the “clinical test that includes polygenic scores to estimate a patient’s risk for one of the world’s leading causes of death”
April 15, 2021 at 12:39 pm
Craken
If these are the best arguments contra embryo selection based on PRS, I would definitely do embryo selection based on PRS–conditional of doing IVF conception in the first place. IVF has its own risks, as you note. Adding genetically informed embryo selection to the standard IVF process is highly likely to be eugenic. And I do not consider “eugenic” a bad word; I wish I were more eugenic; I wish the entire species was more eugenic.
Your central argument, putting aside the PC nonsense about “ethics,” is that because we have limited knowledge to inform our selection decisions, we ought to pick an embryo randomly. That is a non-sequitur. It strikes me as amoral at best given that in some conditions we can produce a PRS in which those on the right tail face a 10x risk of the disease. See the recent paper: “From Phenotype to Genotype: polygenic prediction of complex human traits.”
Also, you fail to mention an obvious point (probably not from ignorance, but from polemic drive): when we select on multiple traits simultaneously, our ability to improve the overall genetic quality of a human increases dramatically. This is because there is little evidence that pleiotropy is a significance hindrance to this strategy: the human genome appears to be sufficiently high dimensional to permit, in theory, large improvements on many traits without much antagonism.
Of course, in contrast to embryo selection, whose time has come for those consigned to IVF, using Crispr or some other genetic engineering technique is currently unethical due to ignorance of the proper targets for modification.
April 15, 2021 at 12:43 pm
Lior Pachter
Just as a point of fact: Orchid is not talking about PES as an addition for couples that have already decided to undergo IVF. It is targeting every couple.
April 19, 2021 at 4:20 am
ziphon
Hey Lior,
Thanks for the interesting right up.
Can you elaborate or link to good reference re risk of eugenics with PES?
I just don’t understand how the risk could be any greater than current options with egg/sperm donations etc. (i.e. you can choose ethnicity of donor. )
Like you have already mentioned I don’t really see PES will really provide a real world advantage. If one embryo has high PRS for condition X its quite likely sibling PRS will be similarly high. So even disregarding issues with poor predictive power will it really be ever that useful even if predictive power improves?
Thanks
Sen
April 23, 2021 at 2:10 pm
Anonymous
https://mendelspod.com/podcasts/orchid-health-first-world-offer-whole-genome-couples-report/ Very bold claims without due diligence, mostly nonsense and of certain concerns.
September 18, 2021 at 12:10 pm
DJ de Koning 💉 💉 (@DJ_de_Koning)
Thanks for this piece, I was not aware Broad claims IP over PRS. That is quite interesting becasue the idea is pretty much derived from what is coined as Whole genome prediction, genomic prediction ec in animal and plant breeding. The main founding paper for that area is by Meuwissen, Hayes and Goddard in Genetics (2001). It has made a huge impact in the area of plant and animal breeding but the implementation (and ethics) are quite different from the proposed use of PRS by this company.