
You are currently browsing the monthly archive for November 2018.
The post concerns Yuval Peres, a principal researcher in the Microsoft Theory Group [update Dec. 26, 2018: YP is no longer employed at Microsoft] and a former colleague of mine at UC Berkeley. Below is a copy of an email sent yesterday to numerous theory of computer science professors worldwide, and published on the Stanford Theory Seminar List. It corroborates information I heard about Yuval Peres a number of years ago when I was a mathematics professor at UC Berkeley. At the time I was asked to keep the information I heard confidential, and I did so because the person who discussed it with me was, understandably, afraid of retaliation. Now I wonder to what extent my silence allowed his harassment of women to continue unabated. I also wonder when the leaders of the statistics department at UC Berkeley, where Peres used to work, and where Terry Speed was a professor emeritus before I reported him, will end their culture of silence.
Hello all,
This is an email composed by Irit Dinur, Oded Goldreich and me. The purpose of this email is to share with you concerns that we had regarding the unethical behavior of Yuval Peres. The behavior we are referring to includes several recent incidents from the past few years, on top of the two “big” cases of sexual harassment that led to severe sanctions against him by his employer, Microsoft, and to the termination of his connections with the University of Washington. Together with two colleagues who are highly regarded and trusted by us, we have first and second-hand testimonies (by people we trust without a shed of doubt) of at least five additional cases of him approaching junior female scientists, some of them students, with offers of intimate nature, behavior that has caused its victims quite a bit of distress since these offers were “insistent”. While the examples that we encountered from the last few years do not fall under the category of sexual harassment from a legal point of view, they certainly caused great discomfort to the victims, who were young female scientists, putting them in a highly awkward situation, and creating an atmosphere that they’d rather avoid (i.e., they would rather miss a conference or a lecture than risk being subjected to repeated intimate offers by him). We wish to stress that his aggressive advances toward young women, usually with no previous friendly connections with him, puts them in a vulnerable position of fearing to cross a senior scientist who might have an impact on their career, which is at a fragile stage. We believe that the questions of whether or not Yuval Peres intended to make them uncomfortable, and whether or not he would or could actually harm their scientific status are irrelevant; the fact is that the victims felt very stressed to a point that they’d rather miss professional events than risk encountering the same situation again. Needless to say, it is the responsibility of senior members of our community to avoid putting less senior members in such a position.
Our current involvement with this issue was triggered by an invitation Yuval Peres received to give a plenary talk at an international conference next year. We felt that this invitation sends a highly undesirable message to our community in general, and to the women he harassed in particular, as if his transgressions are considered unimportant.
We sent an email conveying our concern to the organizers of the conference, suggesting that they disinvite him. With our permission, they forwarded a version of our letter (in which we made changes in order to protect the identity of the women involved) to Yuval Peres. They did not reveal our identity, rather they told him that this is a letter from “senior members of the community”. In our letter we included a paragraph describing a general principle that should be followed. The principle is:
A senior researcher should not approach a junior researcher with an invitation that may be viewed as intimate or personal unless such an invitation was issued in the past by this specific junior to that specific senior. The point being that even if the senior researcher has no intimate/personal intentions, such intentions may be read by the junior researcher, placing the junior in an awkward situation and possibly causing them great distress. Examples for such an invitation include any invitation to a personal event in which only the senior and the junior will be present (e.g., a two-person dinner, a meeting in a private home, etc).
Yuval’s reply was rather laconic, in particular, he did not address the issue of his behavior in the past couple of years. However, he did write:
“I certainly embrace the principle described in boldface in the letter. This seems to be the right approach for any senior scientist these days.”
The reason we are copying this to all of you (as opposed, for example, to using bcc) is related to the islanders’ paradox: we believe that the fact that everyone knows that everyone knows is a significant boost to holding Yuval Peres accountable for his future actions. We’re also bcc’ing several young women who already aware of Yuval Peres’s actions, in order to keep them in the know too.
We understand that sending this out to a large number of people without offering Yuval Peres the chance to respond may be considered unfair. However, after weighing the pros and cons carefully we believe this is a good course of action. First of all, because it is clear that the victims did not invent his offers and their ensuing feelings of anxiety and stress. Secondly, we know that Yuval Peres has been confronted in a face to face conversation by a senior colleague, and it did not end his behavior, so we think it’s important to stay vigilant in protecting the younger members of our community. Thirdly, the information in this letter will reach (or has already reached) almost all of you in any case, so the main effect of the letter is making what everyone knows into public knowledge. Finally, although his response to the organizers did include the minimum of declaring he accepts the guiding principle that we stated, it did not include any reference to the ongoing behavior we described- neither regret nor concern nor denial. So it’s not easy to assume that he truly intends to mend his ways.
We hope that our actions will contribute to the future of our community as an environment that offers all a pleasant and non-threatening atmosphere.
Sincerely,
Irit Dinur, Ehud Friedgut, Oded Goldreich
Last year I wrote a blog post on being wrong. I also wrote a blog post about being wrong three years ago. It’s not fun to admit being wrong, but sometimes it’s necessary. I have to admit to being wrong again.
To place this admission in context I need to start with Mordell’s finite basis theorem, which has been on my mind this past week. The theorem, proved in 1922, states the rational points on an elliptic curve defined over the rational numbers form a finitely generated abelian group. There is quite a bit of math jargon in this statement that makes it seem somewhat esoteric, but it’s actually a beautiful, fundamental, and accessible result at the crossroads of number theory and algebraic geometry.
First, the phrase elliptic curve is just a fancy name for a polynomial equation of the form y² = x³ + ax + b (subject to some technical conditions). “Defined over the rationals” just means that a and b are rational numbers. For example a=-36, b=0 or a=0, b=-26 would each produce an elliptic curve. A “rational point on the curve” refers to a solution to the equation whose coordinates are rational numbers. For example, if we’re looking at the case where a=0 and b=-26 then the elliptic curve is y² = x³ – 26 and one rational solution would be the point (35,-207). This solution also happens to be an integer solution; try to find some others! Elliptic curves are pretty and one can easily explore them in WolframAlpha. For example, the curve y² = x³ – 36x looks like this:

WolframAlpha does more than just provide a picture. It finds integer solutions to the equation. In this case just typing the equation for the elliptic curve into the WolframAlpha box produces:

One of the cool things about elliptic curves is that the points on them form the structure of an abelian group. That is to say, there is a way to “add” points on the curves. I’m not going to go through how this works here but there is a very good introduction to this connection between elliptic curves and groups in an exposition by Tanuj Nayak, an undergrad at Carnegie Mellon University.
Interestingly, even just the rational points on an elliptic curve form a group, and Mordell’s theorem says that for an elliptic curve defined over the rational numbers this group is finitely generated. That means that for such an elliptic curve one can describe all rational points on the curve as finite combinations of some finite set of points. In other words, we (humankind) has been interested in studying Diophantine equations since the time of Diophantus (3rd century). Trying to solve arbitrary polynomial equations is very difficult, so we restrict our attention to easier problems (elliptic curves). Working with integers is difficult, so we relax that requirement a bit and work with rational numbers. And here is a theorem that gives us hope, namely the hope that we can find all solutions to such problems because at least the description of the solutions can be finite.
The idea of looking for all solutions to a problem, and not just one solution, is fundamental to mathematics. I recently had the pleasure of attending a lesson for 1st and 2nd graders by Oleg Gleizer, an exceptional mathematician who takes time not only to teach children mathematics, but to develop mathematics (not arithmetic!) curriculum that is accessible to them. The first thing Oleg asks young children is what they see when looking at this picture:

Children are quick to find the answer and reply either “rabbit” or “duck”. But the lesson they learn is that the answer to his question is that there is no single answer! Saying “rabbit” or “duck” is not a complete answer. In mathematics we seek all solutions to a problem. From this point of view, WolframAlpha’s “integer solutions” section is not satisfactory (it omits x=6, y=0), but while in principle one might worry that one would have to search forever, Mordell’s finite basis theorem provides some peace of mind for an important class of questions in number theory. It also guides mathematicians: if interested in a specific elliptic curve, think about how to find the (finite) generators for the associated group. Now the proof of Mordell’s theorem, or its natural generalization, the Mordell-Weil theorem, is not simple and requires some knowledge of algebraic geometry, but the statement of Mordell’s theorem and its meaning can be explained to kids via simple examples.
I don’t recall exactly when I learned Mordell’s theorem but I think it was while preparing for my qualifying exam in graduate school, when I studied Silverman’s book on elliptic curves for the cryptography section on my qualifying exam- yes, this math is even related to some very powerful schemes for cryptography! But I do remember when a few years later a (mathematician) friend mentioned to me “the coolest paper ever”, a paper related to generalizations of Mordell’s theorem, the very theorem that I had studied for my exam. The paper was by two mathematicians, Steven Zucker and David Cox, and it was titled Intersection Number of Sections of Elliptic Surfaces. The paper described an algorithm for determining whether some sections form a basis for the Mordell-Weil group for certain elliptic surfaces. The content was not why my friend thought this paper was cool, and in fact I don’t think he ever read it. The excitement was because of the juxtaposition of author names. Apparently David Cox had realized that if he could coauthor a paper with his colleague Steven Zucker, they could publish a theorem, which when named after the authors, would produce a misogynistic and homophobic slur. Cox sought out Zucker for this purpose, and their mission was a “success”. Another mathematician, Charles Schwartz, wrote a paper in which he built on this “joke”. From his paper:

So now, in the mathematics literature, in an interesting part of number theory, you have the Cox-Zucker machine. Many mathematicians think this is hilarious. I thought this was hilarious. In fact, when I was younger I frequently boasted about this “joke”, and how cool mathematicians are for coming up with clever stuff like this.
I was wrong.
I first started to wonder about the Zucker and Cox stunt when a friend pointed out to me, after I had used the term C-S to demean someone, that I had just spouted a misogynistic and homophobic slur. I started to notice the use of the C-S phrase all around me and it made me increasingly uncomfortable. I stopped using it. I stopped thinking that the Zucker-Cox stunt was funny (while noticing the irony that the sexual innuendo they constructed was much more cited than their math), and I started to think about the implications of this sort of thing for my profession. How would one explain the Zucker-Cox result to kids? How would undergraduates write a term paper about it without sexual innuendo distracting from the math? How would one discuss the result, the actual math, with colleagues? What kind of environment emerges when misogynistic and homophobic language is not only tolerated in a field, but is a source of pride by the men who dominate it?
These questions have been on my mind this past week as I’ve considered the result of the NIPS conference naming deliberation. This conference was named in 1987 by founders who, as far as I understand, did not consider the sexual connotations (they dismissed the fact that the abbreviation is a racial slur since they considered it all but extinct). Regardless of original intentions I write this post to lend my voice to those who are insisting that the conference change its name. I do so for many reasons. I hear from many of my colleagues that they are deeply offended by the name. That is already reason enough. I do so because the phrase NIPS has been weaponized and is being used to demean and degrade women at one of the main annual machine learning conferences. I don’t make this claim lightly. Consider, for example, TITS 2017 (the (un)official sister event to NIPS). I’ve thought about this specific aggression a lot because in mathematics there is a mathematician by the name of Tits who has many important objects named after him (e.g. Tits buildings). So I have worked through the thought experiment of trying to understand why I think it’s wrong to name a conference NIPS but I’m fine talking about the mathematician Tits. I remember when I first learned of Tits buildings I was taken aback for a moment. But I learned to understand the name Tits as French and I pronounce it as such in my mind and with my voice when I use it. There is no problem there, nor is there a problem with many names that clash across cultures and languages. TITS 2017 is something completely different. It is a deliberate use of NIPS and TITS in a way that can and will make many women uncomfortable. As for NIPS itself perhaps there is a “solution” to interpreting the name that doesn’t involve a racial slur or sexual innuendo (Neural Information Processing Systems). Maybe some people see a rabbit. But others see a duck. All the “solutions” matter. The fact is many women are uncomfortable because instead of being respected as scientists, their bodies and looks have become a subtext for the science that is being discussed. This is a longstanding problem at NIPS (see e.g., Lenna). Furthermore, it’s not only women who are uncomfortable. I am uncomfortable with the NIPS name for the reasons I gave above, and I know many other men are as well. I’m not at ease at conferences where racial slurs and sexual innuendo are featured prominently, and if there are men who are (cf. NIPS poll data) then they should be ignored.
I think this is an extremely important issue not only for computer science, but for all of science. It’s about much more than a name of some conference. This is about recognizing centuries of discriminatory and exclusionary practices against women and minorities, and about eliminating such practices when they occur now rather than encouraging them. The NIPS conference must change their name. #protestNIPS
A few years ago I wrote a post arguing that it is time to end ordered authorship. However that time has not yet arrived, and it appears that it is unlikely to arrive anytime soon. In the meantime, if one is writing a paper with 10 authors, a choice for authorship ordering and equal contribution designation must be made from among the almost 2 billion possibilities (1857945600 to be exact). No wonder authorship arguments are commonplace! The purpose of this short post is to explain the number 1857945600.
At first glance the enumeration of authorship orderings seems to be straightforward, namely that in a paper with n authors there are n! ways to order the authors. However this solution fails to account for designation of authors as “equal contributors”. For example, in the four author paper Structural origin of slow diffusion in protein folding, the first two authors contributed equally, and separately from that, so did the last two (as articulated via a designation of “co-corresponding” authorship). Another such example is the paper PRDM/Blimp1 downregulates expression of germinal center genes LMO2 and HGAL. Equal contribution designations can be more complex. In the recent preprint Connect-seq to superimpose molecular on anatomical neural circuit maps the first and second authors contributed equally, as did the third and fourth (though the equal contributions of the first and second authors was distinct from that of the third and fourth). Sometimes there are also more than two authors who contributed equally. In SeqVis: Visualization of compositional heterogeneity in large alignments of nucleotides the first eight authors contributed equally. A study on “equal contribution” designation in biomedical papers found that this type of designation is becoming increasingly common and can be associated with nearly every position in the byline.
To account for “equal contribution” groupings, I make the assumption that a set of authors who contributed equally must be consecutive in the authorship ordering. This assumption is certainly reasonable in the biological sciences given that there are two gradients of “contribution” (one from the front and one from the end of the authorship list), and that contributions for those in the end gradient are fundamentally distinct from those in the front. An authorship designation for a paper with n authors therefore consists of two separate parts: the n! ways to order the authors, and then the 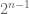

1, 4, 24, 192, 1920, 23040, 322560, 5160960, 92897280, 1857945600, 40874803200, 980995276800, 25505877196800, 714164561510400, 21424936845312000, 685597979049984000, 23310331287699456000, 839171926357180416000, 31888533201572855808000, 1275541328062914232320000.
In the case of a paper with 60 authors, the number of ways to order authors and designate equal contribution is much larger than the number of atoms in the universe. Good luck with your next consortium project!


Recent Comments