
Three years ago Nicolas Bray and I published a post-publication review of the paper “Network link prediction by global silencing of indirect correlations” (Barzel and Barabási, Nature Biotechnology, 2013). Despite our less than positive review of the work, the paper has gone on to garner 95 citations since its publication (source: Google Scholar). In fact, in just this past year the paper has paper has been cited 44 times, an impressive feat with the result that the paper has become the first author’s most cited work.
Ultimate impact
In another Barabási paper (with Wang and Song) titled Quantifying Long-Term Scientific Impact (Science, 2013), the authors provide a formula for estimating the total number of citations a paper will acquire during its lifetime. The estimate is

where 
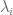

Drive by citations
Now that three years had passed since the publication of the press release and with the ultimate impact revealed, I was curious to see inside the 95 black boxes opened with global silencing, and to examine the 95 wiring diagrams that were thus precisely figured out.
So I delved into the citation list and examined, paper-by-paper, to what end the global silencing method had been used. Strikingly, I did not find, as I expected, precise wiring diagrams, or even black boxes. A typical example of what I did find is illustrated in the paper Global and portioned reconstructions of undirected complex networks by Xu et al. (European Journal Of Physics B, 2016) where the authors mention the Barzel-Barabási paper only once, in the following sentence of the introduction:
“To address this inverse problem, many methods have been proposed and they usually show robust and high performance with appropriate observations [9,10,11, 12,13,14,15,16,17,18,19,20,21].”
(Barzel-Barabási is reference [16]).
Andrew Perrin has coined the term drive by citations for “references to a work that make a very quick appearance, extract a very small, specific point from the work, and move on without really considering the existence or depth of connection [to] the cited work.” While its tempting to characterize the Xu et al. reference of Barzel-Barabási as a drive by citation the term seems overly generous, as Xu et al. have literally extracted nothing from Barzel-Barabási at all. It turns out that almost all of the 95 citations of Barzel-Barabási are of this type. Or not even that. In some cases I found no logical connection at all to the paper. Consider, for example, the Ph.D. thesis Dysbiosis in Inflammatory Bowel Disease, where Barzel-Barabási, as well as the Feizi et al. paper which Nicolas Bray and I also reviewed, are cited as follows:
The Ribosomal Database Project (RDP) is a web resource of curated reference sequences of bacterial, archeal, and fungal rRNAs. This service also facilitates the data analysis by providing the tools to build rRNA-derived phylogenetic trees, as well as aligned and annotated rRNA sequences (Barzel and Barabasi 2013; Feizi, Marbach et al. 2013).
(Neither papers has anything to do with building rRNA-derived phylogenetic trees or aligning rRNA sequences).
While this was probably an accidental error, some of the drive by citations were more sinister. For example, WenJun Zhang is an author who has cited Barzel-Barabási as
We may use an incomplete network to predict missing interactions (links) (Clauset et al., 2008; Guimera and Sales-Pardo, 2009; Barzel and Barabási, 2013; Lü et al., 2015; Zhang, 2015d, 2016a, 2016d; Zhang and Li, 2015).
in exactly the same way in three papers titled Network Informatics: A new science, Network pharmacology: A further description and Network toxicology: a new science. In fact this author has cited the work in exactly the same way in several other papers which appear to be copies of each other for a total of 7 citations all of which are placed in dubious “papers”. I suppose one may call this sort of thing hit and run citation.
I also found among the 95 citations one paper strongly criticizing the Barzel-Barabási paper in a letter to Nature Biotechnology (the title is Silence on the relevant literature and errors in implementation) , as well as the (to me unintelligible) response by the authors.
In any case, after carefully examining each of the 95 references citing Barzel and Barabási I was able to find only one paper that actually applied global silencing to biological data, and two others that benchmarked it. There are other ways a paper could impact derivative work, for example by virtue of the models or mathematics developed, be of use, but I could not find any other instance where Barzel and Barabási’s work was used meaningfully other than the three citations just mentioned.
When a citation is a citation
As mentioned, two papers have benchmarked global silencing (and also network deconvolution, from Feizi et al.). One was a paper by Nie et al. on Minimum Partial Correlation: An Accurate and Parameter-Free Measure of Functional Connectivity in fMRI. Table 1 from the paper shows the results of global silencing, network deconvolution and other methods on a series of simulations using the measure of c-sensitivity for accuracy:

Table 1 from Nie et al. showing performance of methods for “network cleanup”.
EPC is the “Elastic PC-algorithm” developed by the authors, which they argue is the best method. Interestingly, however, global silencing (GS) is equal to or worse than simply choosing the top entries from the partial correlation matrix (FP) in 19/28 cases- that’s 67% of the time! This is consistent with the results we published in Bray & Pachter 2013. In these simulations network deconvolution performs better than partial correlation, but still only 2/3 of the time. However in another benchmark of global silencing and network deconvolution published by Izadi et al. 2016 (A comparative analytical assay of gene regulatory networks inferred using microarray and RNA-seq datasets) network deconvolution underperformed global silencing. Also network deconvolution was examined in the paper Graph reconstruction Using covariance-based methods by Sulaimanov and Koeppl 2016 who show, with specific examples, that the scaling parameter we criticized in Bray & Pachter 2013 is indeed problematic:
The scaling parameter α is introduced in [Feizi et al. 2013] to improve network deconvolution. However, we show with simple examples that particular choices for α can lead to unwanted elimination of direct edges.
It’s therefore difficult to decide which is worse, network deconvolution or global silencing, however in either case it’s fair to consider the two papers that actually tested global silencing as legitimately citing the paper the method was described in.
The single paper I found that used global silencing to analyze a biological network for biological purposes is A Transcriptional and Metabolic Framework for Secondary Wall Formation in Arabidopsis by Li et al. in Plant Physiology, 2016. In fact the paper combined the results of network deconvolution and global silencing as follows:
First, for the given data set, we calculated the Pearson correlation coefficients matrix Sg×g. Given g1 regulators and g2 nonregulators, with g = g1+g2, the correlation matrix can be modified as
where O denotes the zero matrix, to include biological roles (TF and non-TF genes). We extracted the regulatory genes (TFs) from different databases, such as AGRIS (Palaniswamy et al., 2006), PlnTFDB (Pérez-Rodríguez et al., 2010), and DATF (Guo et al., 2005). We then applied the network deconvolution and global silencing methods to the modified correlation matrix S′. However, global silencing depends on finding the inverse of the correlation matrix that is rank deficient in the case p » n, where p is the number of genes and n is the number of features, as with the data analyzed here. Since finding an inverse for a rank-deficient matrix is an ill-posed problem, we resolved it by adding a noise term that renders the matrix positive definite. We then selected the best result, with respect to a match with experimentally verified regulatory interactions, from 10 runs of the procedure as a final outcome. The resulting distribution of weighted matrices for the regulatory interactions obtained by each method was decomposed into the mixture of two Gaussian distributions, and the value at which the two distributions intersect was taken as a cutoff for filtering the resulting interaction weight matrices. The latter was conducted to avoid arbitrary selection of a threshold value and prompted by the bimodality of the regulatory interaction weight matrices resulting from these methods. Finally, the gene regulatory network is attained by taking the shared regulatory interactions between the resulting filtered regulatory interactions obtained by the two approaches. The edges were rescored based on the geometric mean of the scores obtained by the two approaches.

In light of the benchmarks of global silencing and network deconvolution, and in the absence of analysis of the ad hoc method combining their results, it is difficult to believe that this methodology resulted in a meaningful network. However its citation of the relevant papers is certainly legitimate. Still, the results of the paper, which constitute a crude analysis of the resulting networks, are a far cry from revealing the “precise wiring diagram of the system”. The authors acknowledge this writing
From the cluster-based networks, it is clear that a wide variety of ontology terms are associated with each network, and it is difficult to directly associate a distinct process with a certain transcript profile.
The factor of use correction
The analysis of the Barzel and Barabási citations suggests that, because a citation is not always a citation (thanks to Nicolas Bray for suggesting the title for the post), to reflect the ultimate impact of a paper the quantity
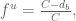
where C is the total number of citations of a paper and 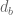

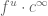
For now I decided to compute the factor of use correction for the Barzel-Barabási paper by generously estimating that 
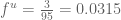


6 comments
Comments feed for this article
January 18, 2017 at 8:04 pm
Morgan Price
This case of drive-by citation seems a bit extreme, but I think the majority of citations do not indicate impact. For example, if I publish a method that is better in situation X than existing methods, and someone uses it (and cites it) in a not-X situation where pre-existing methods are adequate, is this impact? I suspect not. This case might be too subtle for text mining to handle.
January 19, 2017 at 2:04 am
lanthala
I suspect nearly all of these drive-by and hit-and-run citations would be cleared up if citations in the introduction were not counted for purposes of H-index etc; this would require re-citing relevant papers in later sections of journal articles, but would definitely make clearly which citations actually had an impact on the results.
April 11, 2017 at 11:04 am
Dakhoo Naalan (@naarkhoo)
Some people by citing papers from high impact factor journals, aim to brand their work and make it sellable and comparable with works from those journals. I am sure, these 95 papers, not only have cited Barabási recklessly but also other papers from high impact factor journals.
I suggest instead of adjusting citation score, take into account whether citations where really citations, not just citations – in order to decorate the paper from other end by prestigious journal names.
May 6, 2017 at 8:30 am
werepat
@lanthala On one hand I agree that right now just discounting all introduction (and perhaps discussion?) citations would fix 90% the problem. On the other hand, if that became the standard way to count citations, how long would it take for academic culture to adjust and start pushing drive-by citations into the results section? I suppose it depends on the degree to which people are doing it on purpose to curry favor with whoever they’re citing, vs just doing it because it’s the norm. But first the currying-favor people will change their citation patterns (because everyone will prefer to get cited in results), and then possibly that will become the new norm and everyone else will start doing it. … Ugh. Yeah, it’s a difficult problem.
October 12, 2017 at 12:22 pm
amoeba
If in the last sentence you are multiplying 117 with 0.0315, shouldn’t the corrected h-index be 3, not 30? Or did I misunderstand the computation?
October 12, 2017 at 3:23 pm
Lior Pachter
The reason that the corrected h-index is not just 117*0.0315 is that the factor 0.0315 multiplies the raw citations. The h-index then needs to be recomputed from the corrected citation counts. After multiplying all citation counts by 0.0315 are still 30 papers with at least 30 citations.