
The International Society for Clinical Densitometry has an official position on the number of decimal digits that should be reported when describing the results of bone density scans:
- BMD (bone mineral
density): three digits (e.g., 0.927 g/cm2). • - T-score: one digit (e.g., –2.3).
- Z-score: one digit (e.g., 1.7).
- BMC (bone mineral content): two digits (e.g., 31.76
g). - Area: two digits (e.g., 43.25
cm2). - % reference database: Integer
(e.g., 82%).
Are these recommendations reasonable? Maybe not. For example they fly in the face of the recommendation in the “seminal” work of Ehrenberg (Journal of the Royal Statistical Society A, 1977) which is to use two decimal digits.
Two? Three? What should it be? This what my Math10 students always ask of me.
I answered this question for my freshmen in Math10 two weeks ago by using an example based on a dataset from the paper Schwartz, M. “A biomathematical approach to clinical tumor growth“. Cancer 14 (1961): 1272-1294. The paper has a dataset consisting of the size of a pulmonary neoplasm over time:
 A simple model for the tumor growth is
A simple model for the tumor growth is 



Then we have that 
The power function 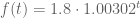

This simple example of decimal digit arithmetic illustrates a pitfall affecting many computational biology studies. It is tempting to believe that 
One field where qualitative results are prevalent, and therefore the devil strikes frequently, is network theory. The emphasis on searching for “universal phenomena”, i.e. qualitative results applicable to networks arising in different contexts, arguably originates with Milgram’s small world experiment that led to the concept of “six-degree of separation” and Watts and Strogatz’s theory of collective dynamics in small-world networks (my friend Peter Dodds replicated Milgram’s original experiment using email in “An experimental study of search in global social networks“, Science 301 (2003), p 827–829) . In mathematics these ideas have been popularized via the Erdös number which is the distance between an author and Paul Erdös in a graph where two individuals are connected by an edge if they have published together. My Erdös number is 2, a fact that is of interest only in that it divulges my combinatorics roots. I’m prouder of other connections to researchers that write excellent papers on topics of current interest. For example, I’m pleased to be distance 2 away from Carl Bergstrom via my former undergraduate student Frazer Meacham (currently one of Carl’s Ph.D. students) and the papers:
- Meacham, Frazer, Dario Boffelli, Joseph Dhahbi, David IK Martin, Meromit Singer, and Lior Pachter. “Identification and Correction of Systematic Error in High-throughput Sequence Data.” BMC Bioinformatics 12, no. 1 (November 21, 2011): 451. doi:10.1186/1471-2105-12-451.
- Meacham, Frazer, Aaron Perlmutter, and Carl T. Bergstrom. “Honest Signaling with Costly Gambles.” Journal of the Royal Society Interface 10, no. 87 (October 6, 2013):20130469. dpi:10.1098/rsif.2013.0469.
“Controllability of complex networks” by Yang-Yu Liu, Jean-Jacques Slotine and Albert-László Barabási, Nature 473 (2011), p 167–173. The mathematics is straightforward: It concerns the dynamics of linear systems of the form
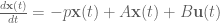
The dynamics can be viewed as taking place on a graph whose adjacency matrix is given by the non-zero entries of A (an nxn matrix). The vector -p (of size n) is called the pole of the linear system and describes intrinsic dynamics at the nodes. The vector u (of size m) corresponds to external inputs that are coupled to the system via the nxm matrix B.
An immediate observation is that the vector p is unnecessary and can be incorporated into the diagonal of the matrix A. An element on the diagonal of A that is then non-zero can be considered to be a self-loop. The system then becomes

which is the form considered in the Liu et al. paper (their equation(1)). The system is controllable if there are time-dependent u that can drive the system from any initial state to a target end state. Mathematically, this is equivalent to asking whether the matrix 
The Liu et al. paper makes two points: the first is that if M is the size of a maximum matching in a given nxn adjacency matrix A, then the minimum m for which there exists a matrix B of size nxm for which the system is structurally controllable is m=n-M+1 (turns out this first point had already been made, namely in a paper by Commault et al. from 2002). The second point is that m is related to the degree distribution of the graph A.
The point of the Cowan et al. paper is to explain that the results of Liu et al. are completely uninteresting if 
Unfortunately for Liu and coauthors, barring pathological canceling out of intrinsic dynamics with self-regulation, the diagonal elements of A, 

“However, infinite time constants at each node do not generally reflect the dynamics of the physical and biological systems in Table 1 [of Liu et al.]. Reproduction and mortality schedules imply species- specific time constants in trophic networks. Molecular products spontaneously degrade at different rates in protein interaction networks and gene regulatory networks. Absent synaptic input, neuronal activity returns to baseline at cell-specific rates. Indeed, most if not all systems in physics, biology, chemistry, ecology, and engineering will have a linearization with a finite time constant. ”
Cowan et al. go a bit further than simply refuting the premise and results of Liu et al. They avoid the naïve reduction of a system with intrinsic dynamics to one with self-loops, and provide a specific criterion for the number of nodes in the graph that must be controlled.
In summary, just as with the rounding of decimal digits, a (simple looking) assumption of Liu et al., namely that 
Oops.

4 comments
Comments feed for this article
September 30, 2013 at 3:49 am
pmelsted
It looks like the condition for Kalman’s criteria of controllability has a latex typo, should be (B,AB,A^2 B,\ldots,A^{n-1}B)
September 30, 2013 at 8:15 am
Lior Pachter
Thanks! Fixed.
December 23, 2013 at 8:22 pm
Indika
Please see this paper for another approach to controllability (controllability gramian)
http://www.pnas.org/content/108/42/17257.abstract
February 23, 2015 at 4:01 am
Aravind Rajeswaran
Sorry to jump in very late, but just wanted to make a quick point. I am not here to defend Barabasi’s work (in fact quite the contrary), but make a subtle point which non control theorists may not be able to spot.
There are two very closely related problems, and the distinction between them is not very obvious. I’ll set the premise as follows – we are given the dynamical system A, and the objective is to choose a B to ensure structural controllability. We have ‘n’ nodes associated with the dynamical system states, the coupling between them as described by A. We further have m input nodes (columns of B) and their interaction with the state nodes are described through B.
1. Minimum independent input selection problem (MIP) – Here the objective is to minimize m i.e. the columns of B. Its obvious as pointed out Cowen et al. that a single driver node is enough to control all the dynamical system provided diagonal entries of A are non zero.
2. Sparse input selection problem (SIP) – Here the objective is to minimize overall cardinality of B. In other words, I don’t really care much about how many driver nodes are needed, but am more concerned with how many edges run between these driver nodes and dynamical system nodes (hence overall cardinality of B). Notice that Cowen’s method requires exactly n couplings, but its easy to show that we can reduce the couplings further.
Both the problems are very important, but have very different applications. Barabasi seems to mix up the two problems and Cowen et al. solely cater to the the first type. For example, MIP is suited for biological applications in drug design to control metabolic networks – to drive them to a desirable steady state and possibly hold them there. SIP on the other hand is more suited for distributed systems applications, where we desire to minimize coupling but ensure control.