
I recently came across a wonderful website of Karl Broman via his homepage. He hosts a list of top ten worst graphs in which he describes examples of badly constructed/displayed graphs from statistical and computational biology papers. He calls out mistakes of others, not in order to humiliate the authors, but rather to educate via example. Its a list every computational biologist should peruse and learn from. The page also has an excellent list of recommended references, including Tufte’s “The visual display of quantitative information” which inspired the Minard plots for transcript abundance shown in Figure 2b and Appendix B of the supplement of my Cufflinks paper.
Interestingly, in addition to the list of graphs, Karl includes a list of tables but with only a single entry (the problem with the table is discussed here). Why should a list of worst graphs have 10 items but a list of tables only one? This is a blatant example of protectionism of tables at the expense of the oft abused graphs. With this post I’d like to remedy this unfair situation and begin the process of assembling a list of top ten worst tables: the tabular hall of shame.
I begin by offering Supplementary Table S6 from the paper “Evidence for Abundant and Purifying Selection in Humans for Recently Acquired Regulatory Functions” by Luke Ward and Manolis Kellis, Science 337 (2012) 1675–1678:

The table is in support of a main result of the paper, namely that in addition to the 5% of the human genome conserved across mammalian genomes, at least another 4% is subject to lineage-specific constraint. This result is based on adding up the estimates of constrained nucleotides from Table S6 (using column 10, the derived allele frequency measure). These estimates were calculated using a statistic that is computed as follows: for each one of ten bins determined according to estimated background selection strength, and for every ENCODE feature F, the average derived allele frequency value DF was rescaled to
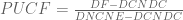
where DCNDC and DNCNE are the bin-specific average derived allele frequencies of conserved non-degenerate coding regions and non-conserved non-ENCODE regions respectively.
One problem with the statistic is that the non-conserved regions contain nucleotides not conserved in all mammals, which is not the same as nucleotides not conserved in any mammals. The latter would be needed in order to identify human specific constraint. Second, the statistic PUCF is used as a proxy for the proportion under constraint even though, as defined, it could be less than zero or greater than one. Indeed, in Table S6 there are four values among the confidence intervals for the estimated proportions using derived allele frequency that include values less than 0% or above 100%, for example:


Ward and Kellis are therefore proposing that some features might have a negative number of nucleotides under constraint. Moreover, while it is possible that PUCF might correlate with the true proportion of nucleotides under constraint, there is no argument provided in the paper. Thus, while Ward and Kellis claim to have estimated the proportion of nucleotides under constraint, they have only computed a statistic named “proportion under constraint”.
The bottom line is that a table containing percentages should not have negative entries, and if it does reader beware!
On his worst graphs website Karl provides one example of a what he calls “a really bad table” and here I have offered a second (amazingly Table S5 from the Ward-Kellis paper is also a candidate for the list– Nicolas Bray and I review its sophistry in an arXiv note– but I think every paper should be represented only once on the list). I ask you, the reader, to help me round out the list by submitting more examples in the comments or by email directly to me. Tables from my papers are fair game (notably example #10 of a bad graph on Karl’s list is from one of his own papers). Please help!

2 comments
Comments feed for this article
October 8, 2013 at 8:16 am
Darya Filippova
I find this list of “ugly” visualizations funny and sad (most are outside the domain of science): http://flowingdata.com/category/visualization/ugly-visualization/
July 4, 2014 at 12:18 am
sidetable
Right here is the right site for everyone who hopes to understand this topic.
You know a whole lot its almost hard to argue with you (not that I really will
need to…HaHa). You definitely put a new spin on a subject which has been discussed
for years. Great stuff, just great!