
Here are two IQ test questions for you:
- Fill in the blank in the sequence 1, 4, 9, 16, 25, __ , 49, 64, 81.
- What number comes next in the sequence 1, 1, 2, 3, 5, 8, 13, .. ?
Please stop and think about these questions before proceeding. Spoiler alert: the blog post reveals the answers.
First, don’t feel bad if it took you a while to answer these questions. In fact, if you didn’t answer them at all that’s a very good thing and I commend you (more on this later). But if you do have answers in mind, you can check them now. The answer key:
- 72
- 12
The pattern that explains why the answer to the first question is 72 may be subtle, but it’s simple. If the nth number in sequence is f(n), then it’s clear that f(n) is just the period of the sequence b(m) defined by 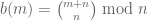
Now I know what you’re thinking. You’re a so-called high intelligence quotient person and you know the answer is different. You think the pattern is just the squares 1², 2², 3², 4², 5², 6², 7², 8², 9² and that the blank should therefore be filled in with number 6² = 36. You think that it makes more sense because its a “simpler” pattern that explains the data. You are planning to comment on this post and you will invoke Occam’s razor. You will say this problem has appeared on many IQ tests with the answer 36 so that is what is expected in terms of an answer. You will explain that therefore it is the answer.
But what is a “simple” pattern? Let’s look at the second question. Here the simplest pattern that can explain the data is just that each number is the sum of the digits of the previous two numbers. So the next number in the sequence is 12 (=1+3+8). Yes, twelve. You shouldn’t be surprised that you got this wrong as well, and I know you did. Addition of digits of numbers is a common ingredient in sequence patterns on IQ tests. For example the problem of finding the next number in the sequence 58, 26, 16, 14, .. is a similar, albeit more difficult, IQ test question that is analogous my #2. But I know that you might have something else in mind. You’re thinking Fibonacci. You’re thinking there was a typo and 12 should have been 21. But I’m sorry.. no, no, no, no. An IQ test is not a math test. It’s about finding patterns, it is a test of raw intelligence.
What has happened here is that by merely asking you these two questions, I’ve forced you to overfit. There simply isn’t a meaningful way to choose a pattern from an enormous set of possibilities using only a handful of numbers. Yet this is exactly what I asked you to do, and what IQ tests ask one to do. They force one to overfit. You know what one should call a test that encourages poor statistics hygiene? A “statistics deficit test” (SD test) instead of an “intelligence quotient test”.
The mathematician Richard Guy uses many alliterations to describe the horror of overfitting from a handful of numbers:
Superficial similarities spawn spurious statements.
Capricious coincidences cause careless conjectures.
Early exceptions eclipse eventual essentials.
Initial irregularities inhibit incisive intuition.
These all capture the point that, as Guy says, “there aren’t enough small numbers to meet the many demands made of them”. For many good examples see his paper:
Richard K. Guy, The strong law of small numbers, The American Mathematical Monthly, 1988.
My favorite example of a pattern that is not what it appears to be is the sequence 1,1,1,1,1,1,1,1,1,1,1,.. continued for a total of 8424432925592889329288197322308900672459420460792432 times, and then followed by the number 8936582237915716659950962253358945635793453256935559. To understand this sequence one has to only identify what is an extremely obvious pattern. The nth term of the sequence is the greatest common divisor of two polynomials: n17+9 and (n+1)17+9. The greatest common divisor is therefore one for n up to 8424432925592889329288197322308900672459420460792432. Then the 8424432925592889329288197322308900672459420460792433rd greatest common divisor is 8936582237915716659950962253358945635793453256935559. Ok, maybe not so obvious and a somewhat unusual construction for a pattern. However this example makes another point. There cannot be certainty to the “solutions” on an IQ test, so that the term “answer” is a misnomer and its use is problematic. If a test asked for the 8424432925592889329288197322308900672459420460792433rd term of the sequence of ones above it is likely that it’s a one, but one cannot know for sure. Another way to say this is that IQ tests are implicitly asking test takers to accept null hypotheses instead of asking, at most, for a rejection.
There has been much debate on what IQ tests really measure and what they predict. But it seems to me that the answer is obvious. In order to score well on IQ tests one must be willing to overfit and to practice the p-value fallacy. Since such practices are synonymous with poor data science, I hypothesize that
low IQ scores predict excellence in data science.


36 comments
Comments feed for this article
June 4, 2018 at 7:52 am
Zingo
IQ tests are generally multiple choice and only one answer will be correct.
June 4, 2018 at 8:39 am
Artem Kaznatcheev
IQ tests usually have the choices as numbers, not the candidate generating functions. Thus having only a few choices of numbers as the answer is not actually a restriction on the hypothesis class (of possible generating functions for the sequence) and thus doesn’t really alleviate the problem of over-fitting.
In particular, we could just give exclusively binary sequences and then have a choice of (a) 0 or (b) 1 and Lior could recreate the same sort of tricks. Although maybe they’ll be less cheeky.
June 4, 2018 at 9:57 am
Zingo
But then it doesn’t matter – the answer will be correct regardless of the uniqueness of the generating function.
June 4, 2018 at 8:23 am
Devang Mehta
“Here the simplest pattern that can explain the data is just that each number is the sum of the digits of the previous two numbers.”
This is not obvious to me and I suspect to most members of H. sapiens who think in a language that involves punctuation 🙂
June 4, 2018 at 8:47 am
Artem Kaznatcheev
I know that your post is tongue-in-cheek but I wish that your hypothesis could be true, and that success (slyly shifting from your use of “excellence”) in data science was determined by intrinsic properties like not being bad at statistics. But since data scientist is a “high status” job, and IQ tests often feel more like “socio-economic desirability” certificates than tests of intrinsic properties…
June 4, 2018 at 10:50 am
Julian Jamison
Why is “sum of the digits of the previous two numbers” simpler than “sum of the previous two numbers”? They seem pretty similar to me.
June 4, 2018 at 5:29 pm
Lior Pachter
Any 5 year old kid will attest that adding up 1+3+8 is simpler than 13+8. With numbers things only get more difficult (and therefore complicated), whereas with digit addition it’s always simpler with numbers <=9.
June 4, 2018 at 6:03 pm
A K
How is it simpler in this case when 1+3+8 will force you to do two-digit addition and 13+8 will also force you to do two-digit addition? I’m not sure what your metric of ‘simplicity’ is.
June 4, 2018 at 11:33 pm
Julian Jamison
Here’s another example: 9999999 and 1, or 1111111111 and 1. In each case adding them as numbers is trivial (you don’t even have to count the 9’s or 1’s; you can just visually line up your answer), whereas adding the digits is noticeably harder. Remember that my claim (the two methods are not obviously comparable) is much weaker than yours (one method is clearly simpler than the other)… especially in light of this very blog post 🙂 But I’ll ask my son when he turns five in a few months, and then we’ll know.
July 5, 2018 at 4:37 am
Matt Oates (@ultimatto)
Not sure I like the idea that something being more difficult to calculate is inherently more complicated. Your addition of three numbers is one extra addition, I could use base 16 and suddenly its two digits and a single addition for D+8. So your claim of simplicity and easiness is spurious *at best* and totally false in practice. Some difficult things are more complicated but things can scale and difficulty without additional complexity.
June 4, 2018 at 11:39 am
PE
You are playing a little with the notion of simplicity. I can’t see how extracting digits before a sum is simpler than just the sum, but maybe tenured math professors code directly on Turing machines, what do I know? In python, my solution would be 1. def f(n): return n**2 2. def f(n) return 1 if n <= 1 else f(n-1) + f(n-2) (forget efficiency) One has 4 tokens and the other 18 if I am not wrong. Other measures of complexity, like number of nodes in a parse tree, may be better, open to other ideas or languages. But I struggle to see your solutions as simpler, probably due to my very average IQ (and in fact I work as a data scientist, and I am greatly concerned with overfitting).
June 4, 2018 at 2:44 pm
sverona
Spivak’s _Calculus_ presents a similar pattern-finding exercise as a “perspicacity test,” which neatly sidesteps the problem here.
June 4, 2018 at 7:54 pm
inverseBWT(u$__anhnhidatdtSuoKauArrhrg)
Lior is way too smart to believe what he types in his post. In the case of this specific post, and I am like many of his posts, he *must* be running some kind of a social experiment to gather ‘statistics’ on the effect of persuasion in this befuddled post-truth world 😉 — is my explanation simple enough, Lior? 😉
More seriously, here’s my $0.02’s worth:
Regarding “what is a simple pattern?”, a concrete treatment to simplicity/complexity of any hypothesis (based on observed data) can be handled information theoretically, and be quantified (in bits or nits). Kolmogorov complexity handles this theoretically, but Wallace’s statistical and inductive inference by Minimum Message Length (MML) embodies this more practically by linking lossless compression with statistical inference.
If the likelihood ratio between two alternative hypotheses on observed data is 1 (as in the series stated in the post), the bias in the prior ratio would help us prefer one hypothesis over another.
In MML, this is tantamount to saying that, if the second parts of the two-part lossless encoding (explaining the some observed data using different hypotheses) are the same, then the difference in the first parts of the respective two-part explanation messages can be used to select the simplest hypothesis. Note, both first part and second part, i.e., I(H) and I(D|H), are measures of Shannon’s Information content, where I(.) = -log(Pr(.)).
Moreover, the post claims that for the second series: “the simplest pattern that can explain the data is just that each number is the sum of the digits”. Notice, this hypothesis ‘fits’ the observed data/series (with 0 error) only in base 10. If data undergoes any invertible transformation (say base_2 or even factoradic base) the hypothesis although simple, does not explain the data well.
On the other hand, the obvious explanation of ‘Fibonacci’ numbers related over second order recurrence — or should one say ‘Hemachandra’ numbers, subject to Stigler’s law of eponymy 🙂 — holds even over invertible transformations of the original series.
So, it isn’t true that the two hypotheses are equally good, let alone equally simple.
Indeed, “pluralitas non est ponenda sine necessitate”, if you don’t just believe Ockham but also Bayes and Shannon.
June 6, 2018 at 12:56 am
Dan
Lior, very nice try! You wrote “I’ve forced you to overfit.” I would argue that your model (of how you generated the data) is unnecessarily complex!
Basically, you are using a Rube Goldberg machine here https://en.wikipedia.org/wiki/Rube_Goldberg_machine .
The model complexity and and fitting errors have been study extensively in information theory. See Kolmogorov complexity https://en.wikipedia.org/wiki/Kolmogorov_complexity ,
Akaike information criterion, Bayesian information criterion, Minimum description length criterion, Normalize maximum likelihood criterion, etc.
Regarding this sequence 1,1,1,1,1,1,1,1,1,1,1,.. continued for a total of 8424432925592889329288197322308900672459420460792432 times, and then followed by the number 893658223791571665995096225335894563579345325693555. One can compress/represent this sequence as 1,8424432925592889329288197322308900672459420460792432,893658223791571665995096225335894563579345325693555. Let’s call this model M1. The other competing model suggested by you is M2 that is “nth term of the sequence is the greatest common divisor of two polynomials: n17+9 and (n+1)17+9”. One puts M1 in file called lp1.txt (which has 107 bytes) and M2 in file called lp2.txt (96 bytes). After compressing them using gzip one has lp1.txt.gz has 94 bytes and lp2.txt.gz has 108 bytes. Actually compressing lp2.txt increaseshe size of the file so it is better not to compress it. According to this simplest model which explain your sequence is actually 1,8424432925592889329288197322308900672459420460792432,893658223791571665995096225335894563579345325693555 (it requires 94 bytes) and not “nth term of the sequence is the greatest common divisor of two polynomials: n17+9 and (n+1)17+9” (it requires 96 bytes). So your model is unnecessarily complex.
December 17, 2018 at 1:16 pm
Unconvinced
The polynomial description is shorter in any language that allows things like “f(n) = gcd(n^17+9,(n+1)^17 + 9)” [26 characters].
December 18, 2018 at 12:31 am
Dan
Very nice try but it was not even close! What is gcd?
R says:
—————————-
> gcd(3,10)
Error in gcd(3, 10) : could not find function “gcd”
—————————-
Therefore your corrected code is this:
“library(fraction); f(n) = gcd(n^17+9,(n+1)^17 + 9)” which has ~50 characters and not 26!
June 6, 2018 at 5:13 am
Dan
> But what is a “simple” pattern?
One way is to compare two patterns or models is to look to their codelengths (that is the number of bits or bytes needed to describe the model) according to MDL criterion. For example f(n)=n^2, that is model M1, takes 8 bytes (because it has 8 characters) whilst f(n)=(m+n,n)modn, that is model M2, takes 16 bytes (because it has 16 characters). It takes twice more bytes to describe the model M2!!! Therefore model M2 is unnecessarily complex according to MDL criterion. Both models M2 and M1 fit equally well the data.
> Another way to say this is that IQ tests are implicitly asking test takers to accept null hypotheses instead of asking, at most, for a rejection.
One assumption is that IQ tests are made for testing humans. They are not made for computers. Therefore the IQ tests aim for the common sense in humans which for many people would mean trying to optimize the trade off between goodness of the fit and the complexity of the model.
June 6, 2018 at 5:24 am
Dan
Let’s look to 1, 1, 2, 3, 5, 8, 13, ..
You wrote “Here the simplest pattern that can explain the data is just that each number is the sum of the digits of the previous two numbers. ”
Model M1: x_n=x_n-1+x_n-2 (this takes 15 bytes because it has 15 characters) [This I could even make it shorter the codelength by just writing Fibonacci]
Model M2 (using digits): “sum of the digits of the previous two numbers” (this takes 45 bytes because it has 45 characters). [Here I use human description because the R/Python code would be much longer than 45 characters (see: https://stackoverflow.com/questions/18675285/digit-sum-function-in-r ). If one is able to come with a R/python/… code that does this in less than 45 characters let me know!]
Therefore model M1 again wins hands down (because it is simpler and it describes that data as well as M2)!
June 30, 2018 at 3:55 am
highrpm
stupid. just go any and say it in a single sentence: low IQ good.
IQ don’t matter. tell that to google, inc. or intel. inc. in fact, i’ll try that in my next interview when HR asks me to take a test.
July 3, 2018 at 1:16 pm
Mike
The problem with Dan’s argument is that Kolmogorov complexity is not computable, which renders it useless for answering questions about which hypothesis that generated the data is simpler. This is a major part of Lior’s point: questions on IQ tests are not actually well-posed. A crucial component of intellectual maturity is the ability to understand the difference between a well-posed problem and an ill-posed one. Therefore, IQ tests can actually select against people who are careful and rigorous.
July 3, 2018 at 3:00 pm
Dan
Hi Mike!
I used MDL criterion and not Kolmogorov complexity and therefore I do not see your point!
Also, the IQ tests are meant to be solved by a large number of people and therefore one who takes them should keep in mind that. The IQ test as the names says is for measuring the intelligence of people and most likely they they are not measuring how careful and rigorous the people are. If this would be the case then probably the IQ test would be called Carefullness and rigorousness test.
July 5, 2018 at 10:14 am
Mike
My point is that the minimum length required to describe a hypothesis is not itself computable. I don’t think it’s reasonable conclude anything meaningful from an eleven year-old’s ability to correctly guess what mental model some IQ test designer had in mind for generating a sequence of numbers or shapes.
December 18, 2018 at 12:32 am
Dan
Mike, I just computed the minimum length code!
December 18, 2018 at 1:15 pm
Mike
No, you didn’t.
December 18, 2018 at 10:41 pm
Dan
Mike, I suggest gently that you read some papers/books of Rissanen about Minimum Description Length and Normalized Maxmium Likelihood before saying that the codelength was not computed here.
December 20, 2018 at 12:37 pm
Mike
I don’t need to read any books. To know that you’ve computed the minimum description of an object, you would have to run all possible computer programs from shortest to longest; some of them would fail to halt; therefore the minimum description length is not computable. What you have produced is a valid upper bound on the minimum description length.
December 20, 2018 at 1:00 pm
Dan
Mike, you are not describing MDL! You are describing totally something else which has nothing to do with MDL and NML. I computed the MDL codelength (the two-part code) using the the MDL principle that is described shortly here: https://en.wikipedia.org/wiki/Minimum_description_length
where
Final_codelength = codelength_of_model + codelength_for_transmitting_the_errors (which is zero here).
Here the codelength of the model is computed by transmitting the model in clear without any compression.
For example, NML computes a stochastic complexity which is a sum of code lengths of all possible models of a given class. See: https://lpl.psy.ohio-state.edu/documents/MNP.pdf
It is not clear to me why you go on and on with “all possible programs” when I computed the two-part code MDL codelength.
December 21, 2018 at 1:25 pm
Mike
You don’t know that your description length is the minimum one. It is shorter in the encoding that you’ve chosen, but the choice of encoding is arbitrary. You would need to run all possible computer programs shorter than the length to see if there are ones that are shorter than yours that have the correct output. You can’t do that in finite time because some Turing programs will not halt, hence the minimum description length is not computable. You’ll never know for sure that there isn’t a shorter encoding out there.
July 28, 2018 at 2:20 pm
blogreader555
There is a problem with terminology here. Using prior knowledge to alleviate a small-sample problem is not overfitting. Sure, the prior knowledge itself may be incorrect or misspecified, but I would still not call it overfitting. The latter is reserved for when an unwarranted inference is made from a small sample by purely data-driven approaches.
September 19, 2018 at 1:43 pm
Pavel Krapivsky
I am very late (just came from the most recent post), but let me mention an IQ test I’ve failed yesterday. Here is a sequence 14,34,42,72,96,110,116,…
It was given in conjunction with some well-known math sequences (Euler numbers, etc.). I had no idea at all (apart perhaps from a conjecture that it is an even number). The solution turned out to be simple and the number happened to be odd, viz. 125; the numbers were the street stops of some express bus in Manhattan.
September 20, 2018 at 4:34 am
Lior Pachter
Ha!
Probably taken from https://ocw.mit.edu/courses/electrical-engineering-and-computer-science/6-046j-introduction-to-algorithms-sma-5503-fall-2005/readings/l12_skiplists.pdf
September 27, 2018 at 1:35 pm
Keith Douglas
The philosopher Mario Bunge has made a similar point in his work on the philosophy of science, in the context of selecting hypotheses. In “math world” the questions have no answers. Even “best” or “simplest” is not defined (because there is no unique similarity metric, etc.) In the real world, then one needs a hypothesis about what one is measuring (or counting), hence how the numbers are generated. (He too tells a story about bus numbers and the like.)
December 17, 2018 at 12:57 pm
Unconvinced
I’m not a fan of IQ tests, but your post shows why the standard answers are the right ones, i.e. the alternatives are worse.
1. Sum of digits is more complex in that it uses extra structure (base 10) overlaid on the integers.
2. There are many cases of the Fibonacci sequence being a useful extrapolation, and essentially none where base 10 sum of digits is useful.
So a person who gives the Fibonacci answer may be more “intelligent” in that his heuristics may work better out-of-sample. Isn’t that what intelligence is supposed to mean?
For the first puzzle, there is likewise the experience that a simple monomial pattern is often useful, such as scaling laws that are everywhere. The number theoretic answer fits the data, but a type of function where f(n) is reduced mod n is almost nonexistent even there. Again someone whose intuition goes with the standard answer will more often “win”.
If your idea was to show that people who can ALSO come up with alternative answers are smarter in some sense, I think that has been used as a metric for creativity in some psychological studies (rate of production of additional explanations).
December 19, 2018 at 1:43 pm
blogreader555
I think the larger conclusion here, beyond simple IQ tests, is that “data-driven science” is impossible. There are an uncountably infinite number of smooth curves that pass through a given finite number of points. Without human intelligence and human context, the problem is hopelessly ill-posed.
January 22, 2019 at 5:41 am
FredB
As the Brits say, “Too clever by half.”
January 22, 2019 at 6:02 am
Bob
That was a fun read, but you’re doing it wrong!
When an IQ test asks “Fill in the blank in the sequence” then really, it’s like when a woman asks you if her new dress makes her look fat, you’re expected to just get that the actual question has nothing to do with what she says…
The question is “what do the psychologists who wrote that question want me to answer?” It’s like riddles, those usually have tons of correct answers but you gotta guess which is the expected one.
That can get interesting, as you demonstrate with the “sum of digits” stuff. In every day adult life, adding numbers is done so often that it becomes almost unconscious but adding digits is almost never done unless you’re into numerology or dissecting IQ tests. Therefore, adding numbers is a much simpler operation for me than adding digits. Maybe not for you, but if you want to argue otherwise, you’ll need to come up with a definition of simplicity that is not subjective.
Sure, IQ tests are all about overfitting. Assuming that the question is actually what’s written on the paper is also overfitting.